索行启言实践团想做一个可以帮助语障儿童发音训练的产品,队员们需要准确识别出语障儿童的发音,并且可以分析出语障儿童的具体发音问题,再给出针对儿童的个性化训练方案。
现在市面上没有能够很好的识别出语障儿童发音的模型,大多是针对普通话或方言识别的模型,因此,队员们为实现精确区分语言障碍患者的声音特征与常人的不同之处,并准确理解其言语含义,需要自行微调并部署一个专门的模型。经过一番详尽的研究和比较后,最终选定“Whisper”作为基础语音识别模型。
有了基础模型后,可以用来训练关于语障儿童的优质数据集从哪里获得又是一个新的难题。
要让模型能够有效识别语言障碍患者的表达,需要一个专为此类人群设计的语音识别模型。在这个过程中,除了要搜集语言障碍患者的声音样本外,还需要找到高质量的数据集来进行训练。经过长时间的搜寻,队员们终于发现了一套优质的数据集。
但是对模型的训练不是一件简单的事,经过反复调试,不记得程序跑崩了多少次,系统崩溃了多少次,最终,调整后的模型可以准确地识别出语障儿童的发音。
下面是队员们训练后的模型和普通模型的效果对比:
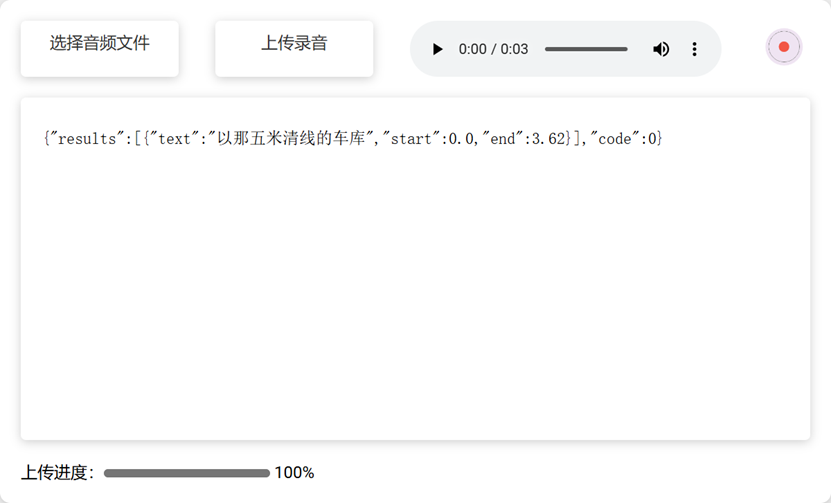
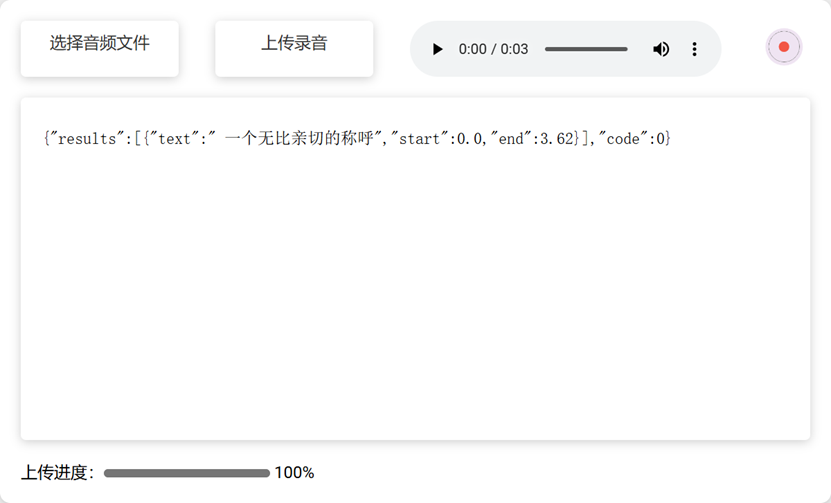
经过训练后的模型已经可以满足要求,为了确保用户能够获得流畅的体验,同时减轻用户设备的压力,队员们经过几番讨论,最终决定将语音识别模型部署在服务器端。这样一来,用户无需担心本地计算资源不足的问题,即可享受到高效准确的服务。
可以识别出语障儿童的语音后,队员们下一步就是需要分析出儿童的发音问题,由于能力和团队限制,没能联系上任何做这方面研究的老师或机构,并且这个领域在国内很少有人去专门研究。
功夫不负有心人,队员们在查找各种文献资料后,终于找到了一个专业的声学特征提取项目——praat。为了更好地实现想要的效果,队员们一边从病理层面学习发音原理和语障分析标准,一边学习praat的使用方法,努力设计算法实现通过准确的声学特征来判断语障问题。
经过重重困难,每天都熬夜奋斗,最主要的语音识别模型和分析模型终于可以实现各自的功能了。
(责编:王钰健)




