喜报——7篇!顶会录用,喜讯连连!
近日,计算机与通信工程学院7篇论文被国际人工智能顶级会议AAAI 2025录用,分别来自物联网与电子工程系、三维图像认知与仿真实验室和计算机科学与技术系、模式识别与人工智能技术创新实验室,祝贺老师同学们!
研究成果介绍
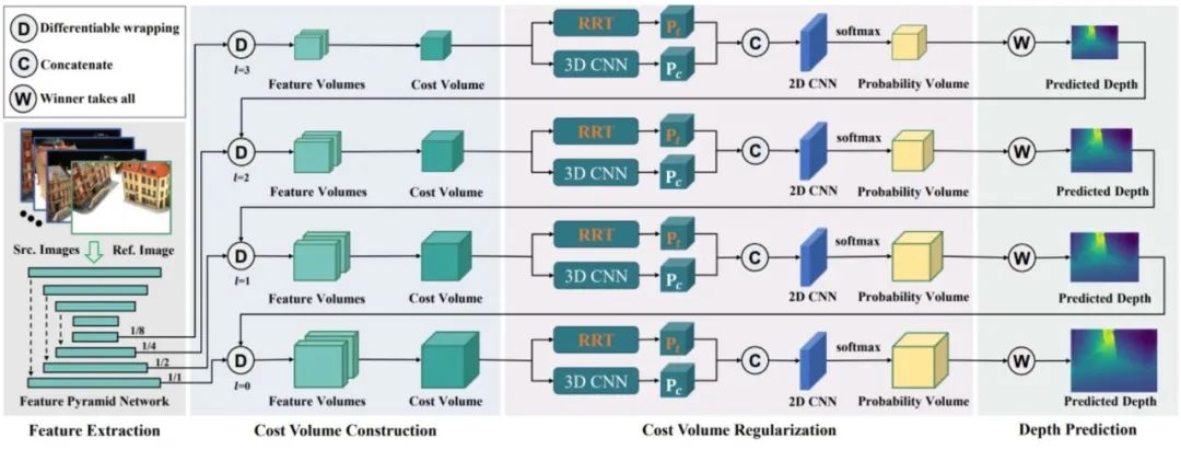
01 RRT-MVS: Recurrent Regularization Transformer for Multi-View Stereo
作者:江健非 导师:马惠敏
论文概述:
本文提出一种用于多视图立体视觉的循环正则化(Transformer),通过对代价体的深度维度和空间维度分别进行正则化,有效地克服了深度图不准确,尤其是在边界和背景区域会出现显著噪声问题的不足。通过开发循环自注意力(Recurrent Self-Attention, R-SA),在每个代价图内和不同代价图之间聚合全局匹配信息并过滤掉嘈杂的特征相关性;提出深度残差注意力(Depth Residual Attention, DRA),用于在代价体中聚合深度相关性;设计位置适配器(Positional Adapter, PA),以增强每个二维代价图中的三维位置感知,从而进一步提升R-SA的效果。实验结果表明,RRT-MVS在DTU和Tanks-and-Temples数据集上达到了最新的性能水平。在所有已发表的方法中,RRT-MVS在Tanks-and-Temples数据集的中级和高级基准中均排名第一。
02 A2RNet: Adversarial Attack Resilient Network for Robust Infrared and Visible Image Fusion
作者:李嘉伟 导师:陈健生
论文概述:
红外与可见光图像融合 (infrared and visible image fusion, IVIF) 是通过将来自不同模态的特有信息集成到一张融合图像中来增强视觉性能的关键技术。现有的方法更注重与未受干扰的数据进行融合,而忽略了故意干扰对融合结果有效性的影响。为了研究融合模型的鲁棒性,本文提出了一种新型对抗攻击网络(A2RNet),该网络以Unet为基础范式,采用基于Transformer的防御细化模块,借助鲁棒由粗到细方式保证融合图像质量,最终实现对抗攻击和训练的目的。与之前研究相比,该方法不仅减轻了对抗性干扰带来的不利影响,还始终保持高保真融合结果,同时,A2RNet在对抗攻击模式下依旧可以保证良好的下游任务表现。

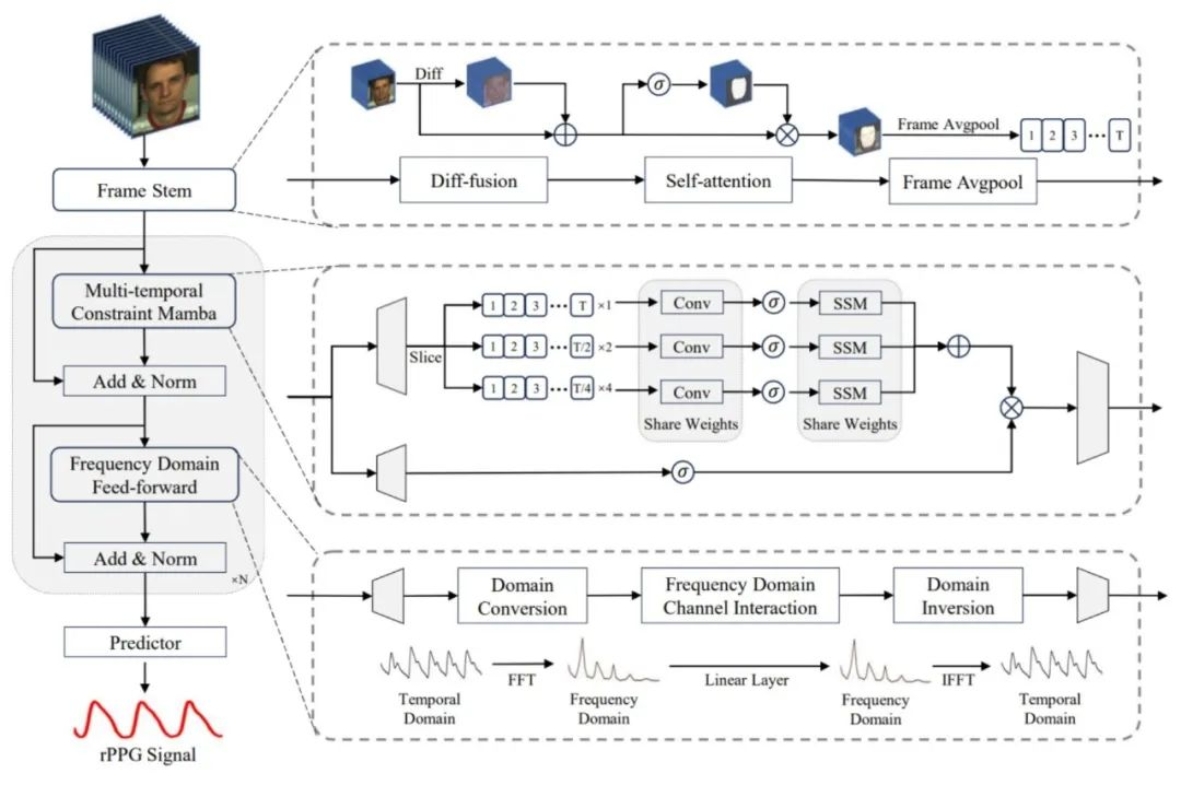
03 RhythmMamba: Fast, Lightweight, and Accurate Remote Physiological Measurement
作者:郭子正 导师:邹博超
论文概述:
远程光电容积脉搏波描记法(rPPG)是一种从面部视频中非接触式测量生理信号的方法,在医疗健康、情感计算和生物防伪检测等多个应用领域中具有巨大潜力。本文提出了一种基于状态空间模型的方法(RhythmMamba),在保持线性复杂性的同时能够捕获长距离依赖,同时解决了rPPG周期性模式和存在大量时空冗余两个核心问题。通过提出的Frame Stem将rPPG任务视为时间序列任务,脉搏波的周期性变化被建模为状态转换,并设计了多时序约束和频域前馈,与rPPG时间序列的特性高度对齐,提升了Mamba对rPPG信号的学习能力。大量实验表明,RhythmMamba以297%的吞吐量和24%的峰值显存占用实现了SOTA的非接触生理信号检测性能。
04 ProtoCar: Learning 3D Vehicle Prototypes from Single-View and Unconstrained driving scene Images
作者:刘洪源 导师:马惠敏
论文概述:
现有image-to-3D工作往往在高质量合成数据集上训练,生成的效果局限于卡通风格,并且难以应对真实场景中存在的遮挡以及视角变化幅度大等问题。对此,本文提出一种能够生成高质量3D模型的方法(ProtoCar),通过借助来自激光雷达和图像传感器的真实驾驶数据训练,高效快速地从低质量数据中学习3D几何信息,实现从单视图图像中学习3D汽车原型的目的。具体方法为通过构造Projection Aware Feature Consistency,引导网络生成的3D特征与2D图像特征对齐,引入Mapping Mask来约束几何形状,并采用3D Gaussian splatting来显示表达几何和纹理。研究结果表明,该方法能够适应各种车型和具有挑战的视觉场景,为驾驶场景的3D建模提供了一种可扩展的有效解决方案。

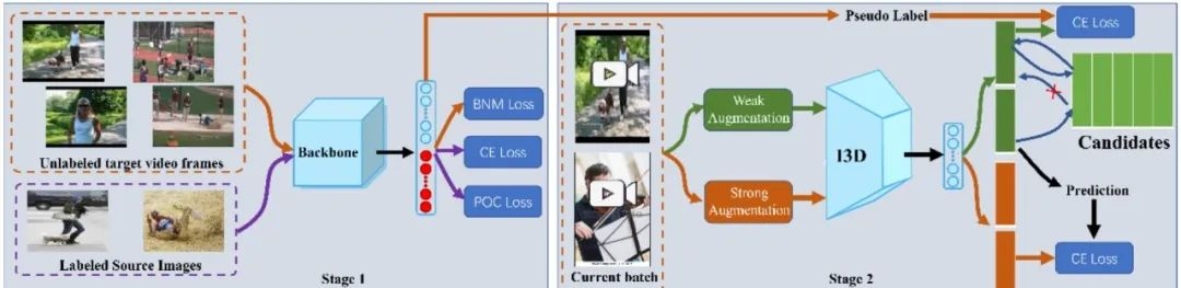
05 Image-to-video Adaptation with Outlier Modeling and Robust Self-learning
作者:卓君宝 通讯:马惠敏
论文概述:
图像到视频的适应任务的目标是充分利用标注图像和未标注视频,从而实现有效的视频识别。图像与视频两种模态间的模态差距,以及两者之间存在的领域差异,构成了这项任务中的两大核心挑战。现有方法通过采用闭集域适应技术来缩小领域差异,但由于存在异常目标域视频帧,导致域对齐不准确;此外,当前方法一般利用从图像级别适应模型得到的伪标签学习一个视频级别模型,忽略了伪标签中的噪音。对此,本文一种全新的两阶段方法,设计了异常类并通过批次核范数最大化损失和伪异常损失最小化来捕捉特定类别的异常帧,提出了一种基于标签传播一致性的新指标,最终达到挑选样本训练更佳视频级别模型的目的。
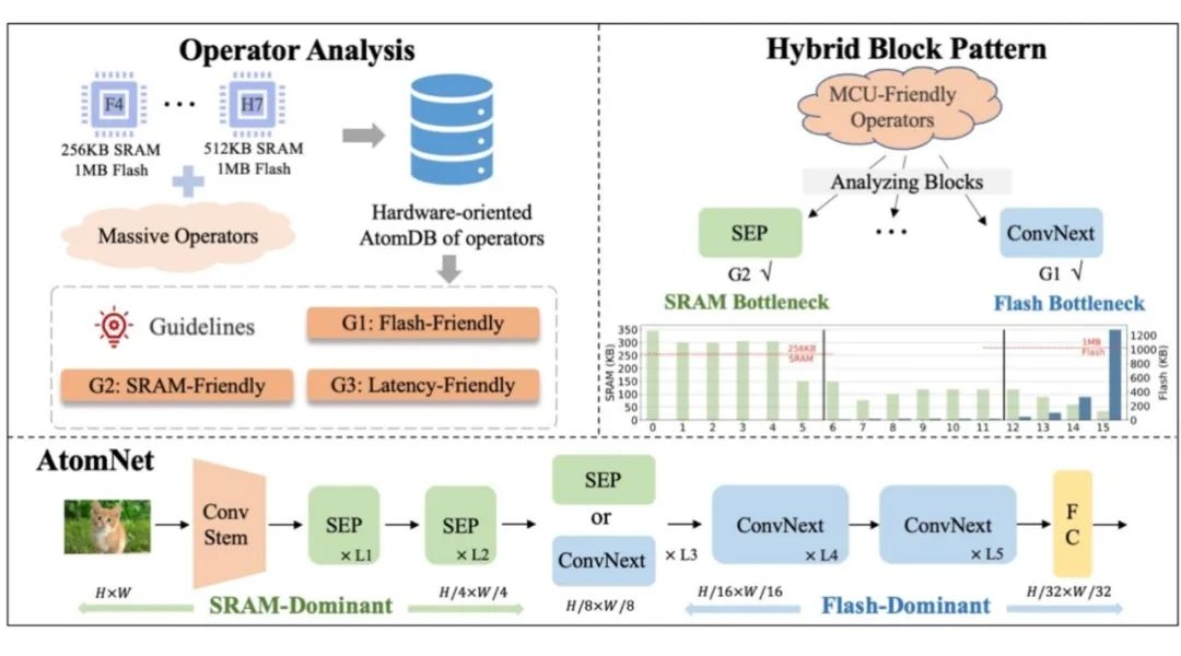
06 AtomNet: Designing Tiny Models from Operators under Extreme MCU Constraints
作者:董志伟 导师:殷绪成
论文概述:
微型机器学习(TinyML)因其在边缘设备上提供低成本和即时性能的能力而受到广泛关注。特别是,常用的微控制器单元(MCU)在峰值内存(SRAM)和存储(Flash)方面施加了极大的限制。为了解决这一问题,本文充分利用 MCU 上的资源,推导出在极端 MCU 限制下设计模型的硬件导向指南,通过收集 Flash、SRAM 和延迟的运行时数据,深入研究原子操作符的信息,构建了数据集(AtomDB)。基于此,建立了操作符指南以充分利用有限的 Flash 和 SRAM,实现最小化延迟。此外,还提出一种混合模式,在不同的网络阶段组织适当的Block,形成一种更具硬件导向的架构AtomNet,旨在解决SRAM和Flash两大瓶颈问题。结果表明,AtomNet 首次在 320KB 的 MCU 上进行ImageNet任务时,实现了3.5%的准确率提升和超过15%的延迟减少,超越了所有当前的最先进方法。
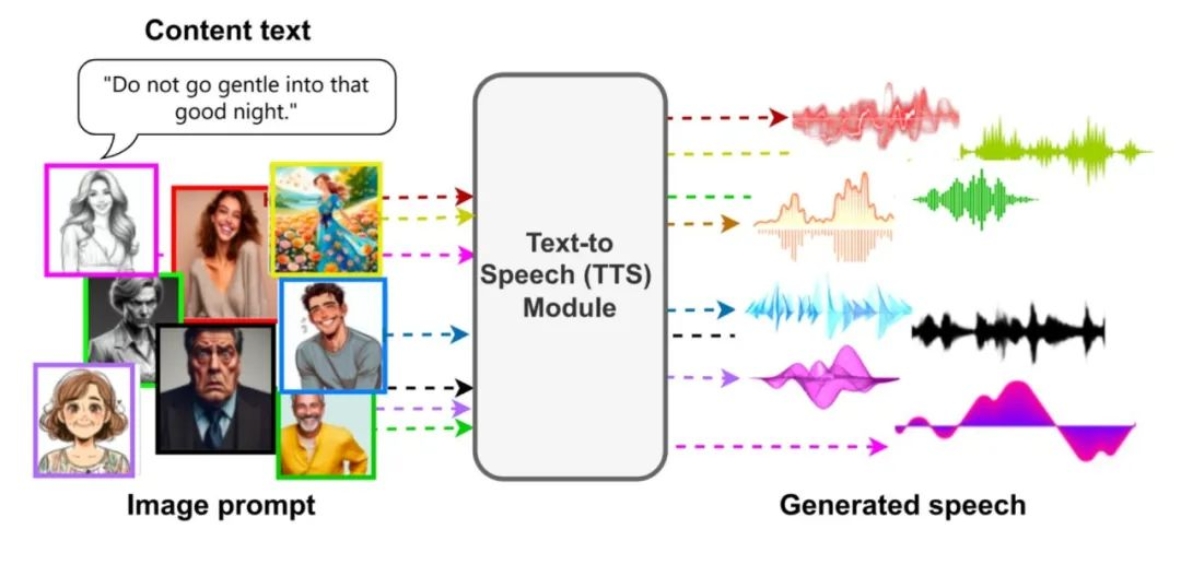
07 FaceSpeak: Expressive and High-Quality Speech Synthesis from Human Portraits of Different Styles
作者:张天昊 导师:殷绪成
论文概述:
人类通过观察说话者的外貌,能够识别其身份、性别、个性及情感等特征,这些特征与说话者的声音风格紧密相关。近年来,随着语音合成技术的进步,越来越多研究开始关注如何增强合成语音的可控性。尽管已有一些基于视觉线索的语音生成方法,但仍存在局限性。为推动这一领域发展,本文创新性地提出了一个多风格、多模态语音合成数据集(EM2TTS),支持训练具有高度一致性和优质输出的语音模型;还提出了一种利用人类肖像图像作为输入的语音合成方法(FaceSpeak),通过解耦身份和情感特征,可精确提取人脸图像中的身份和情感信息,确保生成的语音与说话者的身份特征对齐,同时减少无关因素的干扰,这一设计显著提升了系统的灵活性与多样性。实验结果表明,FaceSpeak能够生成高度一致的语音输出,且语音自然性和音质均有显著提升。
研究团队介绍
三维图像认知与仿真实验室
长期从事复杂环境无人系统视觉认知、人机混合智能研究,将计算机视觉与认知心理学结合,在智能无人系统感认知、数据仿真与智能生成、视觉心智计算等方面取得了系列成果。

模式识别与人工智能技术创新实验室
立足全球人工智能基础研究前沿,专注于模式识别与计算机视觉、机器学习、文档分析与识别、目标检测与人脸识别、人工智能芯片等领域应用研究与技术创新,在工业应用、人工智能芯片等多个领域取得了系列成果。
(责编:王钰健)